Финансовый анализ и инвестиционная оценка предприятия. Прогнозирование финансовых временных рядов
Анализ временных рядов (АВР) – простейший метод восстановления зависимости в детерминированном случае, исходя из заданного временного ряда. Основная задача – экстраполяция (прогноз) – самый постой способ прогноза рыночной ситуации. Суть его – распространение тенденций, сложившихся в прошлом и будущем.
Многие рыночные процессы обладают инертностью, что учитывают при прогнозах. На определенный период следует максимально принимать во внимание вероятность изменения условий функционирования рынка. Делается предположение, что система эволюционирует в достаточно стабильных условиях. Чем система крупнее, тем вероятнее сохранение параметров без изменения, но не на большой срок. Рекомендуется, чтобы период прогноза не превышал 1/3 длительности исходной временной базы.
Временной ряд – серия числовых величин, полученных через регулярные промежутки времени Основное положение, на котором базируется использование временных рядов на предприятии – факторы, влияющие на отклик изучаемой системы, действующие в прошлом, настоящем и подобным образом будут действовать в недалеком будущем.
Цель анализа – оценка и выделение факторов с целью прогноза дальнейшего поведения системы и выработки рациональных УР. Прогноз на основе АВР – краткосрочный, в отношении периода, которого принимается, характеристики изучаемого явления существенно не изменяются. Большинство прогнозных ошибок связано с тем, что прогноз предполагает сохранение прошлых тенденций в будущем. Эта гипотеза редко оправдывается в экономической и общественной жизни.
ВР могут стать плохой основой для разработки прогноза, поэтому методы прогнозирования и АВР применяют для краткосрочного прогнозирования достаточно стабильных и хорошо изученных процессов. Прогнозируемый период не превышает 25-30% исходной временной базы. При использовании уравнения регрессии прогнозные расчеты проводят для оптимистических и пессимистических оценок исходных параметров. Отсюда получают 2 вида прогнозов: оптимистический и пессимистический. Прогнозную оценку, получаемую на основе методов прогнозирования, используют как индикатор желаемой величины прогнозного параметра.
ВР включает в себя:
1) тренд – показывает общий тип изменений, долгосрочного уменьшения и увеличения ряда,
2) сезонные колебания – колебания вокруг тренда, которые возникают на регулярной основе.
Обычно регулярные колебания возникают в период до года. Могут отслеживаться при ежеквартальных, ежемесячных, еженедельных и т.д. наблюдениях.
3) циклические колебания – возникают в периоды свыше года. Часто присутствуют в финансовых данных и связаны с резким спадом, бурным ростом и периодом застоя.
4) случайные колебания – непредсказуемые колебания в большинстве реальных ВР.
Требования к данным временного ряда
Все методы прогнозирования используют математическую статистику, поэтому необходимо, чтобы все данные были сопоставимы, достаточно представлены для проявления закономерности однородные и устойчивые. Невыполнение одного из этих требований делает бессмысленным применение математической статистики.
1. Сопоставимость достигается в результате одинакового подхода, к наблюдениям на разных этапах формирования временного ряда. Данные во временных рядах должны выражаться в одних и тех же единицах измерениях, иметь одинаковый шаг наблюдений, рассчитываться для одного и того же интервала времени по одной и той же методике, охватывать одни и те же элементы, принадлежащие одной территории и относящиеся к неизменной совокупности.
Несопоставимость данных чаще всего проявляется в стоимостных показателях. Даже в тех случаях когда значения этих показателей фиксируются в неизменных ценах. Такого рода несопоставимость временных рядов невозможно устранить чисто формальными методами.
2. Представительность данных характеризуется, прежде всего, полнотой представленных данных. Достаточное число наблюдений определяется в зависимости от цели проводимого исследования. Если целью является описательный статистический анализ, то в качестве изучаемого интервала времени можно выбрать любой интервал по своему усмотрению. Если же цель исследования - построение модели прогнозирования, то число данных исходного временного ряда должно не менее чем в 3 раза превышать период прогноза и не должно быть менее 7 данных. В случае использования квартальных или месячных данных для исследования сезонности и прогнозирования сезонных процессов, исходный временной ряд должен содержать квартальные либо месячные данные не менее чем за 4 года, даже если прогноз требуется на 1 или 2 месяца.
3.Однородность – отсутствие нетипичных аномальных наблюдений, а так же изломов тенденций (изменение). Аномальность приводит к смещению оценок и как следствие к искажению результатов анализа. Формально аномальность проявляется как сильный скачок или спад с последующим приблизительным восстановлением предыдущего уровня. Для диагностики аномальных наблюдений разработаны различные стандартные критерии.
4. Устойчивость – это свойство отражает преобладание закономерности над случайностью в изменениях уровня и ряда. На графиках устойчивых временных рядов даже визуально прослеживается закономерность. А на графиках неустойчивых временных рядов – изменения представлены хаотично. Поэтому поиск закономерностей в таких временных рядах не имеет смысла.
Модели временных рядов
Статистические методы исследования исходят из предположения возможности представления значений временного ряда в виде комбинации нескольких компонентов, отражающих закономерность и случайность развития. В частности для краткосрочных прогнозов применяется аддитивная (адаптивная) и мультипликативная модели.
1. Адаптивная (аддитивная)
Y(t) = T(t) +S(t) + F(t)
t - номер временного интервала
T(t) – тренд развития (долговременная тенденция)
S(t) – сезонная компонента
Е(t) – остаточная компонента
2. Мультипликативная
Y(t) = T(t)*S(t)*F(t)
При односильном постоянстве амплитуды сезонной волны целесообразно использовать аддитивную модель. При изменении амплитуды сезонной волны соответствие с тенденцией среднего уровня используется мультипликативная модель. Иногда используются модели смешанного типа, они дают более точный результат, но содержательно плохо интерпретируются. Применение мультипликативной модели обусловлено тем что в некоторых временных рядах значение сезонной компоненты представляет собой определенную долю трендового значения. Практика показывает что случаи, когда сезонные колебания исследуемого процесса велики и не очень стабильны, мультипликативная модель дает плохие результаты. Сезонная компонента характеризует устойчивые и внутригодичные колебания уровней – она проявляется в некоторых показателях представленных квартальными или месячными данными.
В моделях с аддитивной и мультипликативной компонентой общая процедура анализа примерно одинаковая.
Надо сделать:
1) расчет значений сезонной компоненты
2) вычитание сезонной компоненты из фактических значений – этот процесс называется десезонализации (устранение сезонности)
3) расчет ошибок как разности между фактическими и трендовыми значениями
4) расчет среднего отклонения или средней квадратической ошибки
В прогнозировании также применяются модели кривых роста.
Кривые роста – математические функции предназначенные для аналитического выравнивания временного ряда.
Для описания кривых роста используются следующие функции
2. Парабола Y(t) = a+bt =ct 2
3. Гипербола Y(t) = a +b/t
4. Степенная
5. Показательная
6. Логарифмическая
7. Кривая Джонсона
8. Модифицированная экспонента
Сглаживание временных рядов
Выявление основной тенденции развития называется выравниванием или сглаживание временного ряда. Методы выявления основной тенденции – это методы выравнивания.
Один из наиболее простых приемов обнаружения общей тенденции развития явления – это укрупнение интервала динамического ряда. Для выявления тенденций развития используется метод скользящего среднего или метод экспоненциального сглаживания. Оба метода субъективны в отношении выбора параметров сглаживания. И именно в корректном выборе параметров проявляется интуиция исследователя.
Метод скользящего среднего – крайне субъективен и на результаты сглаживания сильно влияет длина периода сглаживаний. При небольших периодах не удается выявить трендовую компоненту. При больших периодах происходят значительные потери данных на концах анализируемого интервала.
Скользящая средняя порядка L – это временной ряд состоящий из среднеарифметических и среднеарифметических L в соседних значениях функции Y по всем возможным значениям времени. В качестве L – нечетное число, 3, 5,7 - трехточечные, пятиточечные и семиточечные.
Трехточечная схема : среднее значение будет рассчитываться по 3м значениям Yi, одно из которых относится к прошлому периоду, второе к искомому и 3 к будущему периоду. При i = 1 не существует прошлого значение, то в первой точке невозможно рассчитать сглаженное значение. При i = 2 то среднее значение будет средним арифметическим.
В последней точке исходного интервала скользящее среднее также невозможно рассчитать из-за отсутствия будущего значения по отношению к рассчитываемому.
Метод экспоненциального сглаживания – в отличие от скользящего среднего может быть использован для краткосрочным прогнозов в будущей тенденции на один период вперед. Именно поэтому метод обладает явным преимуществом перед предыдущим.
Алгоритм расчета сглаженных значений в любой точке ряда основан на 3х величинах: наблюдаемом значении Yi в данной точке, рассчитанном сглаженном значении для предшествующей точки ряда и некоторым заранее заданным коэффициентам сглаживания, постоянным по всему ряду.
Fi = α*Yi +(α-1)*Fi
Yi –фактическое значение итой точки ряда.
Сглаженное значение для предшествующей точки ряда - (альфа-1)
Альфа может принимать любые значения от 0 до1, но обычно на практике ограничиваются интервалом от 0,2 до 0.5
Метод Хольта. L t =k*Y t +(1-k)*(L t-1 -T t-1), где
L t – сглаженная величина на текущий период;
K – коэффициент сглаживания ряда;
Y t – текущие значение ряда (например, объём продаж);
L t-1 – сглаженная величина за предыдущий период;
T t-1 – значение тренда за предыдущий период.
Методы прогнозирования временных рядов
Для математических методов прогнозирования характерен подбор и обоснование математической модели исследуемого процесса, а также способ определения ее неизвестных параметров. Среди математических методов выделяют методы экстраполяции ввиду их простоты. Методологическая предпосылка экстраполяции состоит в признании преимущественной связи между прошлым, настоящим и будущим.
В настоящее время разработана большая группа экстраполяционных методов прогнозирования временных рядов:
1) Методы, основанные на построении корреляционно-регрессионных моделей. При этом строится модель, включающая набор переменных, от которых зависит поведение функции. Прогноз отличается невысокой точностью, используется при прогнозировании показателей конкретных объектов.
y t = a 0 + a 1 y t -1 + …..+ a n y t-n .
3) Методы, основанные на разложении временного ряда на компоненты – главная тенденция, сезонные колебания, случайная составляющая.
4) Методы, позволяющие учесть неравнозначность исходных данных: метод авторегрессии с последующей адаптацией коэффициентов уравнения, метод взвешенных отклонений.
5) Метод прямой экстраполяции, при котором используются различные трендовые модели. Такие модели используются для краткосрочного прогнозирования временных рядов, например, на небольшое число шагов и т.д.
Построение и анализ коррелограммы позволяет оценить характер и тенденцию изменения во времени прогнозируемого процесса. Если анализируемый ряд имеет тренд и колебания вокруг него или существует явная зависимость между прошлым и будущим ряда (рис.1), коррелограмма при тенденции анализируемого ряда к росту будет отражать убывание положительных коэффициентов корреляции с увеличением временного сдвига
| -0,4 |
| -0,2 |
| 0,2 |
| 0,4 |
| 0,6 |
| 0,8 |
Рисунок 2 - Автокорреляционная функция процесса
Если убывание автокорреляционной функции быстрое, носит экспоненциальный характер, то такие ряды имеют «кратковременную память» и могут быть описаны более сложными моделями автокорреляции – скользящего среднего (модели Бокса- Дженкинса). Более сложным случаем является колебательный затухающий характер корреляционной функции (рис. 2).
Наиболее часто используются простейшие алгоритмы прогнозирования:
По среднему абсолютному приросту при линейной тенденции развития показателя во времени;
По среднему темпу роста, когда тенденция ряда характеризуется показательной кривой;
Аналитическим описанием линии тренда, когда на показатель оказывают влияние множество факторов, и ее рассматривают в виде временной функции;
По корреляционным связям между показателями ряда на ограниченном по времени интервале наблюдения;
По среднему уровню ряда динамики в случае стационарного характера изменения во времени анализируемого показателя и др.
Алгоритм выбирается по характеру линии тренда:
Прогнозирование по среднему абсолютному приросту проводится по формуле:
у пр = у + (Dу)t ;
Прогнозирование по среднему темпу роста Т р:
у пр = уТ р t ,
Прогнозирование средним значением уровня ряда у ср:
у пр = у ср,
Анализ временных рядов позволяет изучить показатели во времени. Временной ряд – это числовые значения статистического показателя, расположенные в хронологическом порядке.
Подобные данные распространены в самых разных сферах человеческой деятельности: ежедневные цены акций, курсов валют, ежеквартальные, годовые объемы продаж, производства и т.д. Типичный временной ряд в метеорологии, например, ежемесячный объем осадков.
Временные ряды в Excel
Если фиксировать значения какого-то процесса через определенные промежутки времени, то получатся элементы временного ряда. Их изменчивость пытаются разделить на закономерную и случайную составляющие. Закономерные изменения членов ряда, как правило, предсказуемы.
Сделаем анализ временных рядов в Excel. Пример: торговая сеть анализирует данные о продажах товаров магазинами, находящимися в городах с населением менее 50 000 человек. Период – 2012-2015 гг. Задача – выявить основную тенденцию развития.
Внесем данные о реализации в таблицу Excel:
На вкладке «Данные» нажимаем кнопку «Анализ данных». Если она не видна, заходим в меню. «Параметры Excel» - «Надстройки». Внизу нажимаем «Перейти» к «Надстройкам Excel» и выбираем «Пакет анализа».
Подключение настройки «Анализ данных» детально описано .
Нужная кнопка появится на ленте.

Из предлагаемого списка инструментов для статистического анализа выбираем «Экспоненциальное сглаживание». Этот метод выравнивания подходит для нашего динамического ряда, значения которого сильно колеблются.

Заполняем диалоговое окно. Входной интервал – диапазон со значениями продаж. Фактор затухания – коэффициент экспоненциального сглаживания (по умолчанию – 0,3). Выходной интервал – ссылка на верхнюю левую ячейку выходного диапазона. Сюда программа поместит сглаженные уровни и размер определит самостоятельно. Ставим галочки «Вывод графика», «Стандартные погрешности».

Закрываем диалоговое окно нажатием ОК. Результаты анализа:

Для расчета стандартных погрешностей Excel использует формулу: =КОРЕНЬ(СУММКВРАЗН(‘диапазон фактических значений’; ‘диапазон прогнозных значений’)/ ‘размер окна сглаживания’). Например, =КОРЕНЬ(СУММКВРАЗН(C3:C5;D3:D5)/3).
Прогнозирование временного ряда в Excel
Составим прогноз продаж, используя данные из предыдущего примера.
На график, отображающий фактические объемы реализации продукции, добавим линию тренда (правая кнопка по графику – «Добавить линию тренда»).
Настраиваем параметры линии тренда:
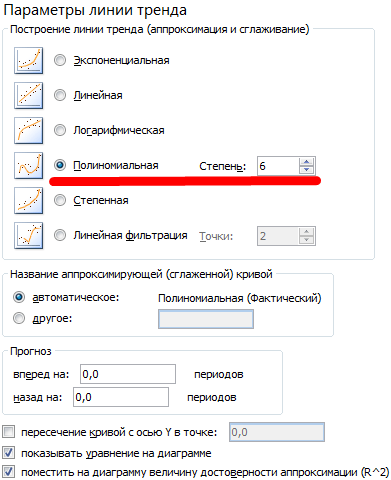
Выбираем полиномиальный тренд, что максимально сократить ошибку прогнозной модели.

R2 = 0,9567, что означает: данное отношение объясняет 95,67% изменений объемов продаж с течением времени.
Уравнение тренда – это модель формулы для расчета прогнозных значений.

Получаем достаточно оптимистичный результат:

В нашем примере все-таки экспоненциальная зависимость. Поэтому при построении линейного тренда больше ошибок и неточностей.
Для прогнозирования экспоненциальной зависимости в Excel можно использовать также функцию РОСТ.

Для линейной зависимости – ТЕНДЕНЦИЯ.
При составлении прогнозов нельзя использовать какой-то один метод: велика вероятность больших отклонений и неточностей.
Скачать полный текст диссертации в формате PDF (2.9 Мб).
Глава 1. Постановка задачи и обзор моделей прогнозирования временных рядов
В текст диссертации включены вставки со ссылками на полезные записи блога, в которых я простым языком рассказываю о моделях прогнозирования и привожу примеры реализации.Нейронные сети рассмотрены в наборе записей по тэгу .
- Модель ARIMAX подробно описана в четырех записях по тэгу .
- Описание и примеры реализации экспоненциального сглаживания приведены по тэгу .
- Опубликованы записи по вопросам .
- Полный перечень материалов о моделях прогнозирования смотри по тэгу .
Слово прогноз возникло от греческого , что означает предвидение, предсказание. Под прогнозированием понимают предсказание будущего с помощью научных методов . Процессом прогнозирования называется специальное научное исследование конкретных перспектив развития какого-либо процесса. Согласно работе процессы, перспективы которых необходимо предсказывать, чаще всего описываются временными рядами , то есть последовательностью значений некоторых величин, полученных в определенные моменты времени. Временной ряд включает в себя два обязательных элемента - отметку времени и значение показателя ряда, полученное тем или иным способом и соответствующее указанной отметке времени. Каждый временной ряд рассматривается как выборочная реализация из бесконечной популяции, генерируемой стохастическим процессом, на который оказывают влияние множество факторов . На представлен пример временного ряда цен на электроэнергию европейской территории РФ.

Рис. 1.1 Временной ряд цен на электроэнергию
Простым языком о видах временных рядов смотри запись блога Характеристики прогнозируемых временных рядов
Одна из классификаций временных рядов приведена в работе . Согласно этой работе, временные ряды различаются способом определения значения, временным шагом, памятью и стационарностью.
- интервальные временные ряды ,
- моментные временные ряды .
Интервальный временной ряд представляет собой последовательность, в которой уровень явления (значение временного ряда) относят к результату, накопленному или вновь произведенному за определенный интервал времени. Интервальным, например, является временной ряд показателя выпуска продукции предприятием за неделю, месяц или год; объем воды, сброшенной гидроэлектростанцией за час, день, месяц; объем электроэнергии, произведенной за час, день, месяц и другие.
Если же значение временного ряда характеризует изучаемое явление в конкретный момент времени, то совокупность таких значений образует моментный временной ряд . Примерами моментных рядов являются последовательности финансовых индексов, рыночных цен; физические показатели, такие как температура окружающего воздуха, влажность, давление, измеренные в конкретные моменты времени, и другие.
В зависимости от частоты определения значений временного ряда, они делятся на
- равноотстоящие временные ряды ,
- неравноотстоящие временные ряды .
Равноотстоящие временные ряды формируются при исследовании и фиксации значений процесса в следующие друг за другом равные интервалы времени. Большинство физических процессов описываются при помощи равноотстоящих временных рядов. Неравноотстоящими временными рядами называются те ряды, для которых принцип равенства интервалов фиксации значений не выполняется. К таким рядам относятся, например, все биржевые индексы в связи с тем, что их значения определяются лишь в рабочие дни недели.
В зависимости от характера описываемого процесса временные ряды разделяются на
- временные ряды длинной памяти ,
- временные ряды короткой памяти .
Задача отнесения временного ряда к рядам с короткой или длинной памятью описана в статье . В целом, говоря о временных рядах с длинной памятью , подразумеваются временные ряды, для которых автокорреляционная функция, введенная в книге , убывает медленно. К временным рядам с короткой памятью относят временные ряды, автокорреляционная функция которых убывает быстро. Скорость потока транспорта по дорогам, а также многие физические процессы, такие как потребление электроэнергии, температура воздуха, относятся к временным рядам с длинной памятью . К временным рядам с короткой памятью относятся, например, временные ряды биржевых индексов.
Дополнительно временные ряды принято разделять на
- стационарные временные ряды ,
- нестационарные временные ряды .
Стационарным временным рядом называется такой ряд, который остается в равновесии относительно постоянного среднего уровня. Остальные временные ряды являются нестационарными . В книге указано, что и в промышленности, и в торговле, и в экономике, где прогнозирование имеет важное значение, многие временные ряды являются нестационарными, то есть не имеющими естественного среднего значения. Нестационарные временные ряды для решения задачи прогнозирования часто приводятся к стационарным при помощи разностного оператора .
Горизонты прогнозирования рассмотрены также в записи блога Горизонты прогнозирования временных рядов
- ультра: до 3 – 4 часа;
- краткосрочное прогнозирование : до 5 – 8 часов;
- : до 16 – 24 часов.
Для задачи прогнозирования энергопотребления классификация задач предложена в работе :
- : до одного дня;
- краткосрочное прогнозирование : от одного дня до недели;
- среднесрочное прогнозирование : от одной недели до года;
- долгосрочное прогнозирование : более чем на год вперед.
То есть для различных временных рядов , с различным временным разрешением классификация срочности задач прогнозирования индивидуальна .
Говоря о прогнозировании временных рядов, необходимо различить два взаимосвязанных понятия - метод прогнозирования и .
Метод прогнозирования представляет собой последовательность действий , которые нужно совершить для получения модели прогнозирования временного ряда.
Метод прогнозирования содержит последовательность действий, в результате выполнения которой определяется конкретного временного ряда. Кроме того, метод прогнозирования содержит действия по оценке качества прогнозных значений. Общий итеративный подход к построению модели прогнозирования состоит из следующий шагов .
Шаг 1. На первом шаге на основании предыдущего собственного или стороннего опыта выбирается общий класс моделей для прогнозирования временного ряда на заданный горизонт.
Шаг 2. Определенный общий класс моделей обширен. Для непосредственной подгонки к исходному временному ряду, развиваются грубые методы идентификации подклассов моделей. Такие методы идентификации используют качественные оценки временного ряда.
Шаг 3. После определения подкласса модели, необходимо оценить ее параметры , если модель содержит параметры, или структуру, если модель относится к категории структурных моделей (). На данном этапе обычно используется итеративные способы, когда производится оценка участка (или всего) временного ряда при различных значениях изменяемых величин. Как правило, данный шаг является наиболее трудоемким в связи с тем, что часто в расчет принимаются все доступные исторические значения временного ряда.
Шаг 4. Далее производится диагностическая проверка полученной модели прогнозирования . Чаще всего выбирается участок или несколько участков временного ряда, достаточных по длине для проверочного прогнозирования и последующей оценки точности прогноза. Выбранные для диагностики модели прогнозирования участки временного ряда называются контрольными участками (периодами).
Шаг 5. В случае если точность диагностического прогнозирования оказалась приемлемой для задач, в которых используются прогнозные значения, то модель готова к использованию . В случае если точность прогнозирования оказалось недостаточной для последующего использования прогнозных значений, то возможно итеративное повторение всех описанных выше шагов, начиная с первого.
Моделью прогнозирования временного ряда является функциональное представление, адекватно описывающее временной ряд.
При прогнозировании временных рядов возможны два варианта постановки задачи . В первом варианте для получения будущих значений исследуемого временного ряда используются доступные значения только этого ряда . Во втором варианте для получения прогнозных значений возможно использование не только фактических значений искомого ряда, но и значений набора внешних факторов, представленных в виде временных рядов . В общем случае временные ряды внешних факторов могут иметь разрешение по времени отличное от разрешения искомого временного ряда. Например, в работе подробно обсуждаются внешние факторы, оказывающие влияние на временной ряд энергопотребления. К таким внешним факторам относят температуру окружающей среды, влажность воздуха, а также сезонность, т. е. час суток, день недели, месяц года. В общем случае внешние факторы могут быть дискретными , т. е. представленными временными рядами, например, температура воздуха; или категориальными , т. е. состоящими из подмножеств, например, в зависимости от веса тела человека можно отнести к трем категориям: «легкий», «средний», «тяжелый». Лишь некоторые модели прогнозирования позволяют учитывать категориальные внешние факторы, большинство моделей позволяют учитывать только дискретных ().
При прогнозировании временного ряда , адекватно описывающую временной ряд, которая называется моделью прогнозирования . Цель создания модели прогнозирования состоит в получении такой модели, для которой среднее абсолютное отклонение истинного значения от прогнозируемого стремится к минимальному для заданного горизонта, который называется временем упреждения. После того, как модель прогнозирования временного ряда определена, требуется вычислить будущие значения временного ряда, а также их доверительный интервал.
1.2. Формальная постановка задачи
Прогнозирование без учета внешних факторов . Пусть значения временного ряда доступны в дискретные моменты времени t = 1,2,...,T . Обозначим временной ряд Z(t) = Z(1), Z(2),...,Z(T) . В момент времени T необходимо определить значения процесса Z(t) в моменты времени T+1,...,T+P . Момент времени T называется моментом прогноза, а величина P - временем упреждения .
1) Для вычисления значений временного ряда в будущие моменты времени требуется определить функциональную зависимость , отражающую связь между прошлыми и будущими значениями этого ряда

Рис. 1.2. Иллюстрация задачи прогнозирования временного ряда без учета внешних факторов
Прогнозирование с учетом внешних факторов . Пусть значения исходного временного ряда Z(t) доступны в дискретные моменты времени t = 1,2,...,T . Предполагается, что на значения Z(t) оказывает влияние набор внешних факторов. Пусть первый внешний фактор X 1 (t 1) доступен в дискретные моменты времени t 1 = 1,2,...,T 1 , второй внешний фактор X 2 (t 2) доступен в моменты времени t 2 = 1,2,...,T 2 и т.д.
В случае, если дискретность исходного временного ряда и внешних факторов, а также значения T,T 1 ,...,T S различны, то временные ряды внешних факторов X 1 (t 1) ,...,X S (t S) необходимо привести к единой шкале времени t .
В момент прогноза T необходимо определить будущие значения исходного процесса Z(t) в моменты времени T+1,...,T+P , учитывая влияние внешних факторов X 1 (t) ,...,X S (t) . При этом считаем, что значения внешних факторов в моменты времени X 1 (T+1) ,...,X 1 (T+P) ,...,X S (T+1) ,...,X S (T+P) являются доступными.
1) Для вычисления будущих значений процесса Z(t) в указанные моменты времени требуется определить функциональную зависимость , отражающую связь между прошлыми значениями Z(t) и будущими, а также принимающую во внимание влияние внешних факторов X 1 (t) ,...,X S (t) на исходный временной ряд
2) Кроме получения будущих значений требуется определить доверительный интервал возможных отклонений этих значений.
Задача прогнозирования временного ряда с учетом одного внешнего фактора представлена на

Рис. 1.3. Иллюстрация задачи прогнозирования временного ряда с учетом внешнего фактора
1.3. Обзор моделей прогнозирования
Перед тем как перейти к обзору моделей, необходимо отметить, что названия моделей и соответствующих методов как правило совпадают . Например, работы , , , посвящены одной из самых распространенных моделей прогнозирования авторегрессия проинтегрированного скользящего среднего с учетом внешнего фактора (auto regression moving average external, ). Эту модель и соответствующий ей метод обычно называют . В настоящее время принято использовать английские аббревиатуры названий как моделей, так и методов.
Набор понятных для чтения материалов по вопросу классификации моделей и методов прогнозирования временных рядов можно найти по тегу .
Линейная регрессионная модель . Самым простым вариантом регрессионной модели является линейная регрессия. В основу модели положено предположение, что существует дискретный внешний фактор X(t) , оказывающий влияние на исследуемый процесс Z(t) , при этом связь между процессом и внешним фактором линейна. Модель прогнозирования на основании линейной регрессии описывается уравнением
где α 0 и α 1 - коэффициенты регрессии; ε t - ошибка модели. Для получения прогнозных значений Z(t) в момент времени t необходимо иметь значение X(t) в тот же момент времени t , что редко выполнимо на практике.
Множественная регрессионная модель . На практике на процесс Z(t) оказывают влияние целый ряд дискретных внешних факторов X 1 (t) ,…,X S (t) . Тогда модель прогнозирования имеет вид
Недостатком данной модели является то, что для вычисления будущего значения процесса Z(t) необходимо знать будущие значения всех факторов X 1 (t) ,…,X S (t) , что почти невыполнимо на практике.
В основу нелинейной регрессионной модели положено предположение о том, что существует известная функция, описывающая зависимость между исходным процессом Z(t) и внешним фактором X(t)
В рамках построения модели прогнозирования необходимо определить параметры функции A . Например, можно предположить, что
Для построения модели достаточно определить параметры ![]() . Однако на практике редко встречаются процессы, для которых вид функциональной зависимости между процессом Z(t)
и внешним фактором X(t)
заранее известен. В связи с этим нелинейные регрессионные модели применяются редко
.
. Однако на практике редко встречаются процессы, для которых вид функциональной зависимости между процессом Z(t)
и внешним фактором X(t)
заранее известен. В связи с этим нелинейные регрессионные модели применяются редко
.
Модель группового учета аргументов (МГУА) была разработана Ивахтенко А.Г. . Модель имеет вид
 (1.9)
(1.9)
Другой тип модели имеет большое значение в описании временных рядов и часто используется совместно с авторегрессией называется моделью скользящего среднего порядка q и описывается уравнением
Авторегрессионнная модель с распределенным лагом (autoregressive distributed lag models, ARDLM) недостаточно подробно описана в литературе. Основное внимание данной модели уделяется в книгах по эконометрике .
Часто при моделировании процессов на изучаемую переменную влияют не только текущие значения процесса, но и его лаги, то есть значения временного ряда, предшествующие изучаемому моменту времени. Модель авторегрессии распределенного лага описывается уравнением
Здесь φ 0 ,..., φ p - коэффициенты, l - величина лага. Модель () называется ARDLM(p,l) и чаще всего применяется для моделирования экономических процессов .
1.3.3. Модели экспоненциального сглаживания
Примеры реализации экспоненциального сглаживания можно найти по тэгу .
Модели экспоненциального сглаживания разработаны в середине XX века и до сегодняшнего дня являются широко распространенными в силу их простоты и наглядности.
Модель экспоненциального сглаживания (exponential smoothing, ES) применяется для моделирования финансовых и экономических процессов . В основу экспоненциального сглаживания заложена идея постоянного пересмотра прогнозных значений по мере поступления фактических. Модель ES присваивает экспоненциально убывающие веса наблюдениям по мере их старения. Таким образом, последние доступные наблюдения имеют большее влияние на прогнозное значение, чем старшие наблюдения.
Функция модели ES имеет вид
где α - коэффициент сглаживания, 0 < α < 1 ; начальные условия определяются как S(1) = Z(0) . В данной модели каждое последующее сглаженное значение S(t) является взвешенным средним между предыдущим значением временного ряда Z(t) и предыдущего сглаженного значения S(t-1) .
Модель Хольта или двойное экспоненциальное сглаживание применяется для моделирования процессов, имеющих тренд . В этом случае в модели необходимо рассматривать две составляющие: уровень и тренд . Уровень и тренд сглаживаются отдельно
 (1.17)
(1.17)
Здесь α - коэффициент сглаживания уровня, как и в модели (1.16), γ - коэффициент сглаживания тренда.
Модель Хольта-Винтерса или тройное экспоненциальное сглаживание применяется для процессов, которые имеют тренд и сезонную составляющую
Здесь R(t) - сглаженный уровень без учета сезонной составляющей
G(t) - сглаженный тренд
а S(t) - сезонная составляющая
Величина L определяется длиной сезона исследуемого процесса. Модели экспоненциального сглаживания наиболее популярны для долгосрочного прогнозирования .
1.3.4. Нейросетевые модели
Набор читабельных материалов с примерами реализации нейронных сетей можно найти по тэгу
В настоящее время самой популярной среди структурных моделей является модель на основе искусственных нейронных сетей (artificial neural network, ANN) . Нейронные сети состоят из нейронов ().

Рис. 1.4. Нелинейная модель нейрона
Модель нейрона можно описать парой уравнений
 (1.22)
(1.22)
где Z(t-1) ,...,Z(t-m) - входные сигналы; ω 1 ,...,ω m - синаптические веса нейрона; p - порог; φ(U(t)) - функция активации.
Функция активации бывают трех основных типов :
- функция единичного скачка ;
- кусочно-линейная функция ;
- сигмоидальная функция .
Способ связи нейронов определяет архитектуру нейронной сети . Согласно работе , в зависимости от способа связи нейронов сети делятся на
- однослойные нейронные сети прямого распространения ,
- многослойные нейронные сети прямого распространения ,
- рекуррентные нейронные сети .

Рис. 1.5. Трехслойная нейронная сеть прямого распространения
Таким образом, при помощи нейронных сетей возможно моделирование нелинейной зависимости будущего значения временного ряда от его фактических значений и от значений внешних факторов. Нелинейная зависимость определяется структурой сети и функцией активации.
Пример реализации в MATLAB трехслойной нейронной сети для прогнозирования энергопотребоения на 24 значения вперед можно найти в записи блога Создаем нейронную сеть для прогнозирования временного ряда .
1.3.5. Модели на базе цепей Маркова
Модели прогнозирования на основе цепей Маркова (Markov chain model) предполагают, что будущее состояние процесса зависит только от его текущего состояния и не зависит от предыдущих . В связи с этим процессы, моделируемые цепями Маркова, должны относиться к процессами с короткой памятью.
Пример цепи Маркова для процесса, имеющего три состояния , представлен на .

Рис. 1.6. Цепь Маркова с тремя состояниями
Здесь S 1 ,...,X 3 - состояния процесса Z(t) ; λ 12 S 1 в состояние S 2 , λ 23 - вероятность перехода из состояния S 2 в состояние S 3 и т.д. При построении цепи Маркова определяется множество состояний и вероятности переходов. Есть текущее состояние процесса S i , то качестве будущего состояния процесса выбирается такое состояние S i , вероятность перехода в которое (значение λ ij ) максимальна.
Таким образом, структура цепи Маркова и вероятности перехода состояний определяют зависимость между будущим значением процесса и его текущим значением .
1.3.6. Модели на базе классификационно-регрессионных деревьев
Классификационно-регрессионные деревья (classification and regression trees, CART) являются еще одной популярной структурной моделью прогнозирования временных рядов . Структурные модели CART разработаны для моделирования процессов, на которые оказывают влияние как непрерывные внешние факторы, так и категориальные. Если внешние факторы, влияющие на процесс Z(t) , непрерывны, то используются регрессионные деревья; если факторы категориальные, то - классификационные деревья. В случае, если необходимо учитывать факторы обоих типов, то используются смешанные классификационно-регрессионные деревья.

Рис. 1.7. Бинарное классификационно-регрессионное дерево
Согласно модели CART, прогнозное значение временного ряда зависит от предыдущих значений, а также некоторых независимых переменных. На приведенном на примере сначала предыдущее значение процесса сравнивается с константой Z 0 . Если значение Z(t-1) меньше Z 0 , то выполняется следующая проверка: X(t) > X 11 . Если неравенство не выполняется, то Z(t) = C 3 , иначе проверки продолжаются до того момента, пока не будет найден лист дерева, в котором происходит определение будущего значения процесса Z(t) . Важно, что при определении значения в расчет принимаются как непрерывные переменные, например, X(t) , так и категориальные Y , для которых выполняется проверка присутствия значения в одном из заранее определенных подмножеств. Значения пороговых констант, например, Z 0 , X 11 , а также подмножеств Y 11 ,Y 12 выполняется на этапе обучения дерева .
Таким образом, CART моделирует зависимость будущей величины процесса Z(t) при помощи структуры дерева, а также пороговых констант и подмножеств .
1.1.1. Другие модели и методы прогнозирования
Кроме классов моделей прогнозирования , рассмотренных выше, существуют менее распространенные модели и методы прогнозирования . Главным недостатком моделей и методов , упомянутых в настоящем разделе, является недостаточная методологическая база , т. е. недостаточно подробное описание возможностей как моделей, так и путей определения их параметров. Кроме того, в открытом доступе можно найти лишь небольшое количество статей, посвященных применению данных методов.
Метод опорных векторов (support vector machine, SVM) применяется, например, для прогнозирования движения рынков и цен на электроэнергию . В основу метода положена классификация, производимая за счет перевода исходных временных рядов, представленных в виде векторов, в пространство более высокой размерности и поиска разделяющей гиперплоскости с максимальным зазором в этом пространстве. Алгоритм SVM работает в предположении, что чем больше разница или расстояние между этими параллельными гиперплоскостями, тем меньше будет средняя ошибка классификатора . При этом задача прогнозирования решается таким образом, что на этапе обучения классификатора выявляются независимые переменные (внешние факторы), будущие значения которых определяют в какой из определенных ранее подклассов попадет прогноз Z(t) .
Генетический алгоритм (genetic algorithm, GA) был разработан и часто применяется для решения задач оптимизации, а также поисковых задач. Однако некоторые модификации GA позволяют решать задачи прогнозирования.
Важными являются их простота и прозрачность моделирования. Еще одним достоинством является единообразие анализа и проектирования, заложенное в работе . На сегодняшний день данный класс моделей является одним из наиболее популярных , а потому в открытом доступе легко найти примеры применения авторегрессионных моделей для решения задач прогнозирования временных рядов различных предметных областей.
Недостатками данного класса моделей являются: большое число параметров модели, идентификация которых неоднозначна и ресурсоемка ; низкая адаптивность моделей, а также линейность и, как следствие, отсутствие способности моделирования нелинейных процессов, часто встречающихся на практике .
. Достоинствами данного класса моделей являются простота и единообразие их анализа и проектирования. Данный класс моделей чаще других используется для долгосрочного прогнозирования .
Недостатком данного класса моделей прогнозирования является отсутствие гибкости .
Нейросетевые модели и методы . Основным достоинством нейросетевых моделей является нелинейность, т.е. способность устанавливать нелинейные зависимости между будущими и фактическими значениями процессов. Другими важными достоинствами являются: адаптивность, масштабируемость (параллельная структура ANN ускоряет вычисления) и единообразие их анализа и проектирования .
При этом недостатками ANN являются отсутствие прозрачности моделирования; сложность выбора архитектуры, высокие требования к непротиворечивости обучающей выборки; сложность выбора алгоритма обучения и ресурсоемкость процесса их обучения .
Простота и единообразие анализа и проектирования являются достоинствами моделей на базе цепей Маркова .
Недостатком данных моделей является отсутствие возможности моделирования процессов с длинной памятью .
Модели на базе классификационно-регрессионных деревьев . Достоинствами данного класса моделей являются: масштабируемость, за счет которой возможна быстрая обработка сверхбольших объемов данных; быстрота и однозначность процесса обучения дерева (в отличие от ANN) , а также возможность использовать категориальные внешние факторы.
Недостатками данных моделей являются неоднозначность алгоритма построения структуры дерева; сложность вопроса останова т.е. вопроса о том, когда стоит прекратить дальнейшие ветвления; отсутствие единообразия их анализа и проектирования .
Достоинства и недостатки моделей и методов систематизированы в таблице 1.
Таблица 1. Сравнение моделей и методов прогнозирования
| Модель и метод | Достоинства | Недостатки |
|---|---|---|
| Регрессионные модели и методы | простота, гибкость, прозрачность моделирования; единообразие анализа и проектирования | сложность определения функциональной зависимости; трудоемкость нахождения коэффициентов зависимости; отсутствие возможности моделирования нелинейных процессов (для нелинейной регрессии) |
| Авторегрессионные модели и методы | простота, прозрачность моделирования; единообразие анализа и проектирования; множество примеров применения | трудоемкость и ресурсоемкость идентификации моделей; невозможность моделирования нелинейностей; низкая адаптивность |
| Модели и методы экспоненциального сглаживания | недостаточная гибкость; узкая применимость моделей | |
| Нейросетевые модели и методы | нелинейность моделей; масштабируемость, высокая адаптивность; единообразие анализа и проектирования; множество примеров применения | отсутствие прозрачности; сложность выбора архитектуры; жесткие требования к обучающей выборке; сложность выбора алгоритма обучения; ресурсоемкость процесса обучения |
| Модели и методы на базе цепей Маркова | простота моделирования; единообразие анализа и проектирования | невозможность моделирования процессов с длинной памятью; узкая применимость моделей |
| Модели и методы на базе классификационно-регрессионных деревьев | масштабируемость; быстрота и простота процесса обучения; возможность учитывать категориальные переменные | неоднозначность алгоритма построения дерева; сложность вопроса останова |
Нужно дополнительно отметить, что ни для одной из рассмотренных групп моделей (и методов) в достоинствах не указана точность прогнозирования . Это сделано в связи с тем, что точность прогнозирования того или иного процесса зависит не только от модели , но и от опыта исследователя , от доступности данных , от располагаемой аппаратной мощности и многих других факторов. Точность прогнозирования будет оцениваться для конкретных задач , решаемых в рамках данной работы.
В ряде работ , , указано, что на сегодняшний день наиболее распространенными моделями прогнозирования являются авторегрессионные модели (ARIMAX), а также нейросетевые модели (ANN) . В статье , в частности, утверждается: «Without a doubt ARIMA(X) and GRACH modeling methodologies are the most popular methodologies for forecasting time series. Neural networks are now the biggest challengers to conventional time series forecasting methods» . (Без сомнений модели ARIMA(X) и GARCH являются самыми популярными для прогнозирования временных рядов. В настоящее время главную конкуренцию данным моделям составляют модели на основе ANN .)
1.4.2. Комбинированные модели
Одной из популярных современных тенденций в области создания моделей прогнозирования является создание комбинированных моделей и методов . Подобный подход дает возможность компенсировать недостатки одних моделей при помощи других и направлен на повышение точности прогнозирования, как одного из главных критериев эффективности модели.
Одной из первых работ в этой области является статья . В ней предлагается подход, в котором прогнозирование временного ряда осуществляется в два этапа . На первом этапе на основании моделей распознавания образов (pattern recognition) выделяются гомогенные группы (patterns) временного ряда . На следующем этапе для каждой группы строится отдельная модель прогнозирования . В статье указывается, что при комбинированном подходе удается повысить точность прогнозирования временных рядов .
В работе предлагается модель для прогнозирования цен на электроэнергию Испании. При помощи вейвлет преобразования (wavelet transform) доступные значения временного ряда разделяются на несколько последовательностей, для каждой из которых строится отдельная модель ARIMA.
В обзоре моделей прогнозирования энергопотребления рассматривается следующие типы комбинаций:
- нейронные сети + нечеткая логика ;
- нейронные сети + ARIMA ;
- нейронные сети + регрессия ;
- нейронные сети + GA + нечеткая логика ;
- регрессия + нечеткая логика .
В большинстве комбинаций модели на основе нейронных сетей применяются для решения задачи кластеризации , а далее для каждого кластера строиться отдельная модель прогнозирования на основе ARIMA, GA, нечеткой логики и др. В работе утверждается, что применение комбинированных моделей , выполняющих предварительную кластеризации и последующее прогнозирование внутри определенного кластера, является наиболее перспективным направлением развития моделей прогнозирования .
Работа посвящена вопросам кластеризации временных рядов для того, чтобы на основании полученных кластеров выполнять прогнозирование. Для кластеризации предлагается два метода: метод K- cредних (K-mean) и метод нечетких C-средних (fuzzy C-mean). Целью обоих алгоритмов кластеризации является извлечение полезной информации из временного ряда для последующего прогнозирования. Авторы утверждают, что применение кластеризации дает возможность повысить точность прогнозирования.
Применение комбинированных моделей является направлением, которое при корректном подходе позволяет повысить точность прогнозирования . Главным недостатком комбинированных моделей является сложность и ресурсоемкость их разработки : нужно разработать модели таким образом, чтобы компенсировать недостатки каждой из них, не потеряв достоинств.
Ряд исследователей пошли по альтернативному пути и разработали авторегрессионные модели , в основе которых лежит предположение о том, что временной ряд есть последовательность повторяющихся кластеров (patterns). Однако при этом разработчики не создавали комбинированных моделей, а определяли кластеры и выполняли прогноз на основании одной модели . Рассмотрим эти модели подробнее.
В работе предложена модель прогнозирования направления движения индексов рынка (index movement), учитывающая кластеры временного ряда. Пусть временной ряд содержит три значения -1, 0 и 1, которые характеризуют спад, стабильное состояние и подъем рынка соответственно. Кластером (pattern) называется последовательность для i = 1,2,...,N-M , где N - число доступных отчетов временного ряда Z(t) . Для определения прогнозного значения рассмотрена последняя доступная информация, а именно последовательность Z(N,M) = Z(N-M+1),Z(N-M+2),...,Z(N) , для которой определена ближайшая похожая (closet match) Z(Q,M) = Z(Q+1),Z(Q+2),...,Z(Q+M) . При этом функция, определяющая близость, имеет вид
т.е. близость кластеров определяется простым сравнением. Далее вычисляется прогнозное значение
Таким образом, в данной модели предполагается, что если в некоторый момент времени в прошлом рынок вел себя определенным образом, то в будущем его поведение повторится в связи с тем, что временной ряд является последовательностью кластеров.
Еще в двух работах , предложена модель прогнозирования, основанная на модели авторегрессии, но принимающая во внимание кусочки временного ряда . Здесь прогнозное значение временного ряда определено выражением
которое является линейной авторегрессией порядка M . При этом коэффициенты авторегрессии α 0 ,α 1 ,…,α M определяются следующим образом. Предполагается, что существует K кусочков (векторов) длины M временного ряда, для которых выполняется выражение
 (1.28)
(1.28)
При определении ближайших векторов (closest vectors) Z(i 1 -1) ,Z(i 1 -2) ,…,Z(i 1 -M) ,...,Z(i K -1) ,Z(i K -2) ,…,Z(i K -M) в статье использовано значение линейной корреляции Пирсона между всеми возможными векторами и новейшим вектором (last available vector) Z(t-1) , а также, , является перспективным в области создания моделей прогнозирования временных рядов . Предложенная в диссертации модель прогнозирования развивает модели , , и устраняет все перечисленные выше недостатки: модель позволяет учитывать влияния внешних факторов; формулируется критерий определения похожей выборки для двух видов постановок задачи прогнозирования (); количество параметром модели сокращается до одного, что существенно упрощает идентификацию модели.
1.5. Выводы
1) Задача прогнозирования временных рядов имеет высокую актуальность для многих предметных областей и является неотъемлемой частью повседневной работы многих компаний.
2) Установлено, что к настоящему времени разработано множество моделей для решения задачи прогнозирования временного ряда , среди которых наибольшую применимость имеют авторегрессионные и нейросетевые модели .
3) Выявлены достоинства и недостатки рассмотренных моделей . Установлено, что существенным недостатком авторегрессионных моделей является большое число свободных параметров, требующих идентификации; недостатками нейросетевых моделей является ее непрозрачность моделирования и сложность обучения сети.
4) Определено, что наиболее перспективным направлением развития моделей прогнозирования с целью повышения точности является создание комбинированных моделей , выполняющих на первом этапе кластеризацию, а затем прогнозирование временного ряда внутри установленного кластера.
07.10.2013 Тайлер Чессман
Понимание ключевых идей прогнозирования временных рядов и ознакомление с некоторыми деталями даст вам преимущество в использовании возможностей прогнозирования в SQL Server Analysis Services (SSAS)
В этой статье будут описаны основные понятия, необходимые для освоения технологий интеллектуального анализа данных. Кроме того, мы рассмотрим некоторые тонкости, чтобы, столкнувшись с ними на практике, вы не были обескуражены (см. врезку «Почему интеллектуальный анализ данных так непопулярен»).
Время от времени специалистам по SQL Server приходится делать перспективные оценки будущей стоимости, например прогнозы доходов или продаж. Организации иногда применяют технологию интеллектуального анализа данных (data-mining) в построении моделей прогнозирования, чтобы предоставить такие оценки. Разобравшись в основных понятиях и некоторых деталях, вы начнете с успехом использовать возможности прогнозирования в SQL Server Analysis Services (SSAS).
Методы прогнозирования
Существуют различные подходы к прогнозированию. Например, сайт Forecasting Methods (forecastingmethods.org) выделяет различные категории методов прогнозирования, включая казуальные (иначе называемые экономико-математическими), экспертное моделирование (субъективные), временные ряды, искусственный интеллект, рынок прогнозов, вероятностное прогнозирование, моделирование прогнозирования, а также метод прогнозирования на основе референсных классов. Веб-сайт Forecasting Principles (www.forecastingprinciples.com) дает представление о методах в виде методологического дерева, прежде всего разделяя субъективные методы (то есть методы, используемые при недостатке имеющихся данных для количественного анализа) и статические (то есть методы, используемые, когда доступны соответствующие числовые данные). В этой статье я остановлюсь на прогнозировании временных рядов, типе статического подхода, в котором накопленных данных достаточно для прогнозирования показателей.
Прогнозирование временных рядов предполагает, что данные, полученные в прошлом, помогают объяснить значения в будущем. Важно понимать, что в ряде случаев мы имеем дело с деталями, не отраженными в накопленных данных. Например, появится новый конкурент, который может неблагоприятно повлиять на будущие доходы или быстрые изменения в составе рабочей силы, которые могут повлиять на показатели уровня безработицы. В подобных ситуациях прогнозирование временных рядов не может быть единственным подходом. Зачастую различные подходы к прогнозированию объединяют, чтобы обеспечить наиболее точные прогнозы.
Понимание основ прогнозирования временных рядов
Временные ряды – это совокупность значений, полученных в период времени, обычно через равные интервалы. Общие примеры включают количество продаж в неделю, квартальные расходы и уровни безработицы по месяцам. Данные временных рядов представлены в графическом формате, с временным интервалом вдоль оси координат x графика и значениями вдоль оси y, как показано на экране 1.
Если рассматривать, как меняется значение от одного периода до другого и как прогнозировать значения, следует иметь в виду, что данные временных рядов обладают некоторыми важными характеристиками.
- Базовый уровень (Base level). Базовый уровень, как правило, определяется как среднее значение временного ряда. В некоторых моделях прогнозирования базовый уровень обычно определяется как начальное значение данных ряда.
- Тренд (Trend). Тренд, как правило, показывает, как временные ряды изменяются от одного периода к другому. На примере, представленном на экране 1, число безработных имеет тенденцию роста с начала 2008 года до января 2010 года, после чего линия тренда направляется вниз. Информацию о совокупности выборочных данных, использованных для построения диаграмм в данной статье, можно найти во врезке «Расчет уровня безработицы».
- Сезонные колебания. Некоторые значения имеют тенденцию роста или снижения в зависимости от определенных периодов времени, это может быть день недели или месяц в году. Можно рассмотреть пример с продажами в розничных магазинах, пик которых часто приходится на рождественский сезон. В случае с безработицей мы видим сезонный тренд с наивысшими показателями в январе и июле и низкими показателями в мае и октябре, как показано на экране 2.
- Шум (Noise). Некоторые модели прогнозирования включают четвертую характеристику, шум, или ошибку, которая относится к случайным колебаниям и неравномерным движениям в данных. Шум мы здесь рассматривать не будем.
Таким образом, определяя тренд, накладывая линию тренда на базовый уровень и выявляя сезонную составляющую, которая может иметь место при анализе данных, вы получаете модель прогнозирования, которую можно задействовать для составления прогноза значений:
Прогнозируемое значение = Базовый уровень + Тренд + Сезонная составляющая
Определение базового уровня и тренда
Единственный способ определить базовое значение и тренд – это воспользоваться методом регрессии. Под словом «регрессия» здесь понимается рассмотрение взаимосвязи между переменными. В данном случае существует взаимосвязь между независимой переменной времени и зависимой переменной числа безработных. Обратите внимание, что независимая переменная иногда называется прогнозирующим параметром.
Воспользуйтесь таким инструментом, как Microsoft Excel, чтобы применить метод регрессии. Например, вы можете выполнить автоматический подсчет в Excel и добавить линию тренда к графику временных рядов, используя меню Trendline на вкладке Chart Tools Layout или вкладке PivotChart Tools Layout в панели Excel 2010 или Excel 2007. На экране 1 я добавил прямую линию тренда, выбрав режим Linear trendline в меню Trendline. Затем я выбрал More Trendline Options в меню Trendline, а потом – параметры Display Equation on chart («Показывать уравнение на диаграмме») и Display R-squared value on chart («Показывать на диаграмме значение коэффициента детерминации»), см. экран 3.
.jpg) |
| Экран 3. Параметры тренда в Excel |
Этот процесс подгонки линии тренда к накопленным данным называется линейной регрессией (linear regression). Как мы видим на экране 1, линия тренда рассчитывается в соответствии с уравнением, где определяется базовый уровень (8248,8) и тренд (104.67x):
y = 104,67x + 8248,8
Можно представить себе линию тренда как ряд связанных координат осей x-y, куда вы можете включить промежуток времени (то есть ось x) для получения значения (ось y). Excel определяет «лучшую» линию тренда, применяя метод наименьших квадратов (определяемый как R² на экране 1). Линия наименьших квадратов – это линия, которая минимизирует возведенное в квадрат расстояние по вертикали из каждой точки линии тренда к соответствующей точке линии. Среднеквадратические значения позволяют определить, что отклонения выше или ниже актуальной линии не уравновешивают друг друга. На экране 1 мы видим, что R² = 0,5039, то есть линейное соотношение объясняет 50,39 % изменений в статистике безработицы с течением времени.
Определение точной линии тренда в Excel часто включает в себя метод проб и ошибок, наряду с визуальным контролем. На экране 1 прямая линия тренда подходит не самым лучшим образом. Excel предлагает другие варианты линии тренда, которые вы видите на экране 3. На экране 4 я добавил линию скользящей средней за четыре периода, которая строится на основе среднего арифметического показателей текущего и последних установленных периодов временного ряда.
Кроме того, я добавил полиномиальную линию тренда, применив алгебраическое уравнение для построения линии. Заметьте, что полиномиальная линия тренда имеет значение R² - 0,9318, определяющее наилучшее соотношение в выражении связи между независимой и зависимой переменными. Однако более высокое значение R² не обязательно означает, что линия тренда обеспечит качество прогнозной оценки. Существуют другие методы расчета точных прогнозов, которые я вкратце опишу ниже. Некоторые варианты линии тренда в Excel (например, линейная, полиномиальная линии тренда) позволяют делать прогнозы вперед, а также в обратном направлении, с учетом количества периодов, с нанесением полученных значений на график. Кому-то может показаться странным выражение «прогноз в обратном направлении». Лучше всего представить это на примере. Предположим, что новый фактор - быстрое увеличение рабочих мест в государственном секторе (например, рабочие места в Homeland Defense в начале 2000-х годов, временные работники Бюро переписи населения США) - послужил причиной быстрого падения уровня безработицы. Вам нужно сделать прогноз темпов роста нового сектора рабочих мест в обратном направлении в течение нескольких месяцев, а затем пересчитать уровень безработицы, чтобы прийти к сглаженному показателю изменения.
Вы также можете вручную применить уравнение линии тренда для расчета значений на перспективу. На экране 5 я добавил полиномиальную линию тренда с прогнозом на 6 месяцев, сперва убрав данные за последние 6 месяцев (то есть с апреля по сентябрь 2012 года) из исходного временного ряда.
Если сравнить экран 5 с экраном 1, можно заметить, что полиномиальные прогнозы обладают тенденцией роста, что не соответствует нисходящей тенденции (тренду) фактического временного ряда.
Относительно регрессии важно сделать два замечания.
- Как уже упоминалось выше, линейная регрессия включает одну независимую и одну зависимую переменную. Для понимания того, как дополнительные независимые переменные могут объяснить изменения в зависимой переменной, попробуйте построить модель множественной регрессии. В контексте прогнозирования числа безработных в Соединенных Штатах вы можете увеличить R² (и точность прогноза), учитывая коэффициент роста экономики, населения США, а также рост числа нанятых работников. SSAS может вместить множество переменных (то есть регрессоров) в модель прогнозирования временных рядов.
- Алгоритмы прогнозирования временных рядов, включая те, что используются в SSAS, позволяют вычислить автокорреляцию, которая является корреляцией между соседними значениями временного ряда. Модель прогнозирования, которая непосредственно включает автокорреляцию, называется авторегрессивной (AR) моделью. Например, модель линейной регрессии выстраивает уравнение тренда на основе периода (например, 104,67 * x), в то время как в AR модели уравнение строится, исходя из предыдущих значений (например, -0,417 * безработных (-1) + 0,549 * занятых (-1)). AR модель потенциально увеличивает точность прогноза, так как учитывает дополнительную информацию сверх тренда и сезонной компоненты.
Учитываем сезонную составляющую
Сезонная компонента в структуре временного ряда обычно проявляется в связи либо с днем недели, либо с днем месяца, или же с месяцем в году. Как отмечалось выше, число безработных в США обычно растет и сокращается в установленный календарный год. Это верно даже при росте экономики, как показано на экране 2. Иными словами, чтобы сделать точный прогноз, вы должны учесть сезонную составляющую. Один общий подход заключается в применении метода сглаживания сезонных колебаний. В работе Practical Time Series Forecasting: A Hands-On Guide, Second Edition (CreateSpace Independent Publishing Platform, 2012) автор Галит Шмуели рекомендует использовать один из трех методов:
- вычисление скользящего среднего;
- анализ временного ряда на менее детализированном уровне (например, рассмотрите изменения числа безработных поквартально, а не по месяцам);
- анализ отдельных временных рядов (и расчет прогнозов) по сезону.
Базовый уровень и тренд определяются при расчете прогноза с учетом сглаженного временного ряда. Факультативно сезонная составляющая или корректировка могут вновь применяться к прогнозируемым значениям с учетом начальных значений сезонного фактора при работе с методом Хольта-Винтерса. Если вы хотите увидеть, как производятся расчеты с учетом фактора сезонности в Excel, введите в строке поиска в Интернете «метод Винтерса в Excel». Также развернутое объяснение метода Хольта-Винтерса можно найти в руководстве Wayne L. Winston Microsoft Office Excel 2007: Data Analysis and Business Modeling, Second Edition (Microsoft Press, 2007).
Во многих пакетах интеллектуального анализа данных, таких, как SSAS, в алгоритмах прогнозирования временных рядов автоматически учитываются сезонные колебания путем измерения сезонных соотношений и включения их в модель прогнозирования. Тем не менее, возможно, вы захотите установить подсказки о структуре сезонных изменений.
Точность измерений модели прогнозирования
Как уже говорилось, исходная модель (если применять метод наименьших квадратов) не обязательно обеспечивает точность прогнозов. Самый лучший способ проверки точности прогнозных оценок – это разделить временной ряд на два набора данных: один для построения (то есть тренировки) модели и другой – для валидации. Набор данных для валидации будет являться наиболее «свежей» частью в наборе исходных данных, и он идеально охватывает время, равное временной шкале прогноза на будущее. Для проверки (валидации) модели предсказанные значения сравниваются с фактическими значениями. Обратите внимание, что после того, как вы произвели валидацию, модель может быть перестроена с использованием всего временного ряда, так что для прогнозирования будущих значений показателей желательно задействовать новейшие фактические значения.
Когда измеряется точность модели прогнозирования, как правило, возникает два вопроса: как определить точность прогнозной оценки и сколько исторических данных использовать для тренировки модели.
Как определить точность прогнозной оценки? В некоторых сценариях значения, прогнозируемые выше фактических значений, могут быть нежелательны (например, в прогнозах относительно инвестиционной деятельности). В других ситуациях значения, прогнозируемые ниже фактических, могут иметь разрушительные последствия (например, прогнозирование минимальной из выигрышных цен пункта аукциона). Но в случаях, когда вы хотите рассчитать оценку для всех прогнозов (неважно, выше или ниже реальных значений оказываются прогнозные значения), вы можете начать с количественной ошибки в отдельном прогнозе, используя определение:
ошибка = прогнозируемое значение – фактическое значение
При таком определении ошибки есть два популярнейших метода для измерения точности: это средняя абсолютная ошибка, то есть mean absolute error (MAE) и средняя абсолютная ошибка в процентах, или mean absolute percentage error (MAPE). В методе MAE абсолютные значения ошибок прогнозирования суммируются, а затем делятся на общее число прогнозов. Методом MAPE рассчитывается среднее абсолютное отклонение от прогноза в процентах. Для просмотра примеров работы с этими и другими методами для измерения качества прогнозных оценок шаблон Excel (с образцом данных прогнозирования и коэффициентами точности) откройте веб-страницу Demand Metrics Diagnostics Template (demandplanning.net/DemandMetricsExcelTemp.htm).
Сколько исторических данных следует использовать для тренировки модели? Работая с временным рядом, история которого уходит далеко в прошлое, вы можете захотеть включить в модель все исторические данные. Однако подчас дополнительная история не повышает точность прогнозирования. Давние данные могут даже исказить прогноз, если условия в прошлом существенно отличаются от условий в настоящем (например, состав рабочей силы сейчас и в прошлом различен). Мне не попадалась какая-то особая формула или практический метод, которые подсказали бы, какое количество исторических данных необходимо включить, поэтому я предлагаю начать с временных рядов, которые в несколько раз больше, чем временные интервалы прогноза, а затем проверить точность. Далее, попробуйте округлить число истории вверх или вниз и проведите тест повторно.
Прогнозирование временных рядов в SSAS
Прогнозирование временных рядов впервые появилось в SSAS в 2005 году. Для вычисления прогнозных значений алгоритм временных рядов Microsoft (Microsoft Time Series) использовался единый алгоритм под названием autoregressive tree with cross prediction (ARTXP), или дерево с авторегрессией с перекрестным прогнозированием. ARTXP сочетает метод авторегрессии с интеллектуальным анализом данных decision tree (дерево решений), так что уравнение прогноза может измениться (имеется в виду разделение) на основе определенных критериев. Например, модель прогнозирования обеспечит лучшее соответствие (и большую точность прогноза), если сначала предпринять разделение по дате, а затем на основе значения независимой переменной, как показано на экране 6.
.jpg) |
| Экран 6. Пример дерева решения ARTXP в SSAS |
В SSAS 2008 в алгоритме Microsoft Time Series в дополнение к ARTXP начал использоваться алгоритм под названием autoregressive integrated moving average (ARIMA), интегрированное скользящее среднее с авторегрессией, для вычисления долгосрочных прогнозов. ARIMA считается отраслевым стандартом и может рассматриваться как сочетание процессов авторегрессии и моделей скользящего среднего. Кроме того, он анализирует исторические ошибки прогнозирования для улучшения модели.
По умолчанию алгоритм Microsoft Time Series сочетает результаты алгоритмов ARIMA и ARTXP для достижения оптимальных прогнозов. По желанию вы можете отменить данную функцию. Обратимся к документации SQL Server Books Online (BOL):
«Алгоритм тренирует две различные модели одних и тех же данных: одна модель использует алгоритм ARTXP, а другая – алгоритм ARIMA. Затем алгоритм объединяет результаты двух моделей, чтобы разработать наилучший прогноз, охватывающий переменное число временных срезов. Поскольку алгоритм ARTXP больше подходит для краткосрочных прогнозов, им желательно воспользоваться в начале ряда прогнозов. Однако если временные срезы, необходимые для прогнозирования, уходят в будущее, алгоритм ARIMA более значим».
При работе с прогнозированием временных рядов в SSAS вы должны постоянно иметь в виду следующее:
- Хотя в SSAS есть закладка Mining Accuracy Chart, она не работает с интеллектуальным анализом данных для моделей временных рядов. В результате вам следует вручную измерять точность с помощью одного из методов, упомянутых здесь (например, MAE, MAPE), используя для расчетов такой инструмент, как Excel.
- Редакция SSAS Enterprise Edition позволяет разделить один временной ряд на множество «исторических моделей», так что вам не нужно будет вручную разделять данные на наборы данных для тренировки модели и валидации, проверяя точность прогноза. С точки зрения конечного пользователя, есть только одна модель временных рядов, но вы можете сравнить фактические результаты с прогнозируемыми в рамках модели, как показано на экране 7. Если вы не работаете с редакцией Enterprise Edition или не хотите использовать эту функцию, прежде всего вручную разделите данные.
Следующий шаг
В этой статье я познакомил вас с основами прогнозирования временных рядов. Мы также рассмотрели некоторые детали базовых алгоритмов, чтобы они не стали препятствием в обработке временных рядов. В качестве следующего шага я предлагаю вам освоить инструменты прогнозирования временных рядов с SSAS. Образцом может послужить проект, в котором используются данные по безработице, приведенные в данной статье. Затем вы можете ознакомиться с электронным учебным пособием TechNet «Intermediate Data Mining Tutorial (Analysis Services – Data Mining)» (Промежуточные итоги интеллектуального анализа данных (Analysis Services – интеллектуальный анализ данных)) по адресу technet.microsoft.com/en-us/library/cc879271.aspx.
Почему интеллектуальный анализ данных так непопулярен
В последнее десятилетие начали широко применяться технологии бизнес-аналитики business intelligence (BI), такие, как OLAP. В то же время Microsoft занялась продвижением другой BI–технологии, интеллектуального анализа данных, в таких популярных инструментах, как Microsoft SQL Server и Microsoft Excel. Однако технология интеллектуального анализа данных пока не стала ведущей. Почему? Хотя большинство людей может быстро ухватить суть ключевых понятий интеллектуального анализа данных, основные детали алгоритмов неразрывно связаны с математическими понятиями и формулами. Существует большое «расхождение» между высоким уровнем абстрактного понимания и детальным исполнением. В результате интеллектуальный анализ данных рассматривается ИТ-специалистами и промышленными клиентами как «черный ящик», что не способствует широкому внедрению технологии. Данная статья – моя попытка уменьшить «расхождение» в прогнозировании временных рядов.
Расчет уровня безработицы
В основной статье данные для графиков взяты с учетом информации о работающем населении, опубликованной U.S. Bureau of Labor Statistics (http://www.bls.gov/). BLS публикует сведения об уровне безработицы на основании ежемесячного опроса, проводимого Бюро переписи населения США (BLS), экстраполирующего общее число работающих и безработных. В частности, BLS применяет формулу:
Уровень безработицы = безработные/(безработные + работающие)
Примечательно, что, когда речь заходит об уровне безработицы, средства массовой информации обычно приводят выровненный коэффициент сезонности. Сезонная корректировка осуществляется с помощью общей модели, которая называется авторегрессионным проинтегрированным скользящим средним – autoregressive integrated moving average (ARIMA). По сути, это тот же алгоритм, что используется во многих пакетах глубинного анализа данных для прогнозирования временных рядов, включая SQL Server Analysis Services (SSAS). Чтобы получить более подробную информацию о модели ARIMA, используемой BLS, зайдите на веб-страницу X-12-ARIMA Seasonal Adjustment Program (www.census.gov/srd/www/x12a/). Обратите внимание, что в типовом проекте для данной статьи я использовал скорректированные значения сезонных и несезонных колебаний.









- Граница между европой и азией Америка относится к европе
- Как экономить деньги при маленькой зарплате?
- Порядок получения жилищной субсидии для военнослужащих
- Лимит кассы: нормативная база и сроки установления лимита
- Полная система вычетов Алгебраическая форма комплексного числа
- Модель «Совокупный спрос – совокупное предложение Увеличение совокупного спроса вызывает
- Что называется периодом в физике
- Виды и типы недвижимости, их экономическая составляющая Поля инициализаторов типа
- Экономика, население и города Чеченской Республики
- Особенности проведения региональной программы материнский капитал в московской области Региональный материнский капитал программе семья
- Должностная инструкция страхового агента росгосстрах
- Учет материалов на складе и в бухгалтерии
- На вопрос «Можно ли строить дом без разрешения на строительство?
- Ип на осно какие налоги платит?
- Доходы и расходы будущих периодов Как распределить расходы, затрагивающие несколько налоговых периодов
- Экономические циклы, их особенности и виды
- Необходимо знать от чего зависят цены на жилье
- Контрольная работа: Экономическая мысль Древней Греции
- Бухгалтерские проводки по реализации товаров и услуг 1с бухгалтерия 8
- Оборотные активы организации